
Many organizations mistakenly believe that managing their data pipelines is the same as managing their business information, an assumption that frequently leads to costly strategic missteps and failed analytics initiatives. This confusion between the technical management of raw data and the conceptual organization of meaningful information is not merely a semantic debate; it is a foundational blind spot that prevents enterprises from truly harnessing their most valuable asset. The failure to distinguish between these two critical disciplines creates a fractured data landscape where technical infrastructure exists without clear business purpose, and business goals lack the data support to become a reality.
Introduction The Twin Pillars of a Modern Data Strategy
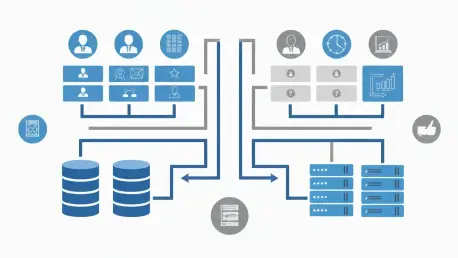
The common but costly confusion between data architecture and information architecture often results in disjointed systems and unreliable insights. Data architecture provides the technical foundation for how raw data is collected, stored, and moved, while information architecture offers the conceptual blueprint for how that data is contextualized and made useful for business operations. Recognizing this distinction is the first step toward managing data as a strategic corporate asset rather than a simple byproduct of business transactions.
This article aims to dismantle this misunderstanding by providing clear definitions for each discipline. It will illustrate their symbiotic relationship and demonstrate how their combined power creates a resilient and adaptive framework for any organization. By understanding how to implement these two architectures in tandem, businesses can move beyond simple data management and begin architecting for genuine, sustainable business value.
The Strategic Advantage Maximizing Business Value Through Dual Architectures
Adopting a dual-architecture approach creates a robust framework that aligns technical capabilities directly with cohesive business strategies, ensuring that data investments produce tangible returns. When the conceptual needs of the business (information architecture) directly guide the construction of the technical infrastructure (data architecture), the entire data ecosystem works in concert. This synergy moves an organization from a reactive state of managing data chaos to a proactive state of leveraging information for competitive advantage.
This integrated approach yields several critical benefits that resonate across the enterprise. It significantly enhances the quality and reliability of business intelligence and analytics, as insights are drawn from data that is not only technically sound but also contextually relevant. Consequently, the pervasive and uncontrolled use of spreadsheet-based analysis and the proliferation of information silos begin to disappear. In their place, a single source of truth emerges, fostering deep organizational trust in the data. This newfound confidence accelerates decision-making, improves operational efficiency, and grants the business the agility needed to respond to market changes with precision and speed.
A Practical Blueprint Implementing the Two Architectures in Tandem
Successfully leveraging these twin pillars requires more than just acknowledging their differences; it demands a practical and integrated implementation plan. Establishing and integrating both architectures is not a linear, one-time project but an ongoing practice that aligns technology with evolving business objectives. The following core best practices provide a blueprint for building a data ecosystem where business context and technical execution are perpetually in sync, creating a powerful engine for growth and innovation.
Best Practice 1 Design a Top Down Business Centric Information Architecture
The journey begins with a top-down, business-centric information architecture (IA) that serves as the conceptual map for the entire enterprise. This framework is not concerned with servers or databases but with how information flows through the organization to support key business processes, applications, and strategic goals. The primary focus is on defining the language of the business in a structured way, capturing the meaning and context that transform raw data points into valuable assets. This involves creating taxonomies to classify information, conceptual data models to define business entities, and process models to map their interactions.
A powerful illustration of this is the process of defining a “customer.” For the marketing department, a customer might be a lead in a campaign pipeline, defined by engagement metrics and demographic data. For sales, a customer is an active opportunity in the CRM system, characterized by purchase history and contract value. Meanwhile, the support team sees a customer as an account with open service tickets and a specific service-level agreement. The information architecture harmonizes these disparate views, creating a unified, 360-degree definition of “customer” that maps the specific information each department needs at every stage of the lifecycle. This ensures that when different teams discuss customers, they are all working from a shared understanding, leading to coherent strategies and seamless experiences.
Best Practice 2 Build a Bottom Up Technically Sound Data Architecture
With the conceptual blueprint from the IA in place, the next step is to construct a bottom-up, technically sound data architecture (DA) to bring it to life. This discipline focuses on designing and implementing the physical infrastructure that manages the entire data lifecycle, from initial collection and storage to complex integration and governance. It is here that abstract business requirements are translated into concrete technical solutions. This involves the careful selection of technologies tailored to the organization’s needs, such as data warehouses for structured analytics, data lakes for handling vast volumes of unstructured data, and various NoSQL databases for flexible, scalable applications.
To support the unified “customer” view defined by the IA, for instance, the data architecture provides the physical reality. A data architect designs the specific database schemas and storage structures needed to hold all the relevant customer attributes from different systems. They then engineer robust data pipelines using tools for ETL (extract, transform, load) or real-time streaming to consolidate customer data from the marketing platform, the CRM, and the support portal into a central repository. Furthermore, the DA implements the necessary data quality rules and master data management processes to cleanse, de-duplicate, and govern this consolidated data, ensuring the “single source of truth” envisioned by the IA is technically sound and reliable for analytics.
Best Practice 3 Cultivate a Symbiotic and Collaborative Relationship
It is a critical error to view information architecture and data architecture as separate, sequential functions. Instead, they must be cultivated as interdependent partners in a continuous dialogue. The IA provides the “what”—the essential business requirements, contextual definitions, and rules—which in turn guides the DA in building the “how”—the appropriate technical implementation that delivers on those needs. Without the IA’s guidance, the DA risks building technically elegant solutions that solve the wrong business problems. Conversely, without a robust DA, the IA remains a theoretical exercise with no power to effect change.
Consider a scenario where the sales department requests a quarterly performance report. A common pitfall is for the data team to simply treat this as a “piping” exercise, moving raw transaction numbers from a source system into a reporting tool. However, this approach misses vital context. The information architecture first defines the crucial business logic: how to calculate sales quotas, what constitutes a “closed-won” deal, and how to attribute sales to specific regions or campaigns. Guided by these definitions, the data architecture then engineers the technical process to extract raw transaction data, apply these complex business rules during transformation, and load the resulting contextualized insights into the business intelligence platform. This collaborative process ensures the final report delivers not just numbers, but actionable information that reflects true business performance.
Best practice 4 Establish Clear and Distinct Professional Roles
To ensure this symbiotic relationship thrives, it is essential to establish clear and distinct professional roles for the Information Architect and the Data Architect. While their work is deeply intertwined, their responsibilities, skills, and organizational focus are unique. Attempting to merge these roles or leaving their boundaries ambiguous leads to gaps in ownership, miscommunication, and ultimately, a disconnect between business strategy and technical execution. Clear delineation of duties ensures accountability and fosters effective, specialized collaboration.
The Information Architect acts as a business-facing liaison, deeply embedded with strategic leaders and subject matter experts to understand and map the enterprise’s information needs. They design the conceptual and logical data models that define business entities and create the taxonomies that structure information for usability. In contrast, the Data Architect is a technical infrastructure specialist who partners closely with IT teams. They take the conceptual requirements defined by the Information Architect and translate them into a physical data framework, selecting the right databases, designing data integration patterns, and overseeing the construction of the underlying platforms. In practice, the Information Architect might work with the marketing VP to define the data required for a new personalization strategy, while the Data Architect works with data engineers to build the real-time data streaming platform needed to execute it.
Conclusion Architecting for a Dynamic Data Driven Future
Ultimately, treating data and information architecture as a unified yet distinct practice proved to be non-negotiable for any organization aspiring to become truly data-driven. The successful separation and subsequent integration of these disciplines allowed enterprises to build a comprehensive data strategy where business context consistently informed technical implementation. This dual approach moved data from a background operational function to a central corporate asset, directly enabling competitive advantage.
This framework delivered the most significant benefits to enterprises of all sizes that were committed to leveraging data for strategic growth. However, its successful adoption depended on several key prerequisites. A clear and well-articulated enterprise data strategy provided the overarching vision, while active executive sponsorship supplied the necessary authority and resources. Most importantly, lasting success required a cultural commitment to treating both architectures not as static projects, but as living frameworks that evolved in lockstep with the business, ensuring sustained relevance and value in a dynamic future.







